
The Power of Internet-Wide Scanning
The Copyleaks Plagiarism Checker API provides a powerful solution for detecting internet plagiarism, allowing you to compare your content against billions of online sources, including websites, articles, and academic journals. When you enable internet scanning, you are tapping into a vast and ever-growing database of online content. This allows you to:- Verify Originality: Ensure that your content is original before publishing.
- Protect Your IP: Discover if your content has been plagiarized and published elsewhere without your permission.
- Maintain SEO Rankings: Avoid penalties from search engines for duplicate content.
Text Moderation for Safe Content
The Copyleaks Text Moderation API is designed to detect harmful content, including hate speech, adult content, and other forms of inappropriate material. This is particularly useful for publishers who want to ensure that their content adheres to community guidelines and standards.Before You Begin
Make sure you are familiar with Copyleaks scans by completing the Check for Plagiarism guide.Verify Content Originality Against Online Sources
Enabling Internet Scanning
To scan your document against internet sources, set theproperties.scanning.internet parameter to true. This enables scanning against all non-paywalled online sources, including a variety of academic journals.
For more information check out our documentation for URL scans, OCR scans, and File scans.
Enable Internet Scanning
Receiving Results
Once your scan is completed, you’ll receive the results through the completed webhook event. This webhook is triggered when the scan process finishes successfully and contains the output information from the scan. The internet plagiarism results will be located in theresults.internet array within the webhook payload. Each internet match includes:
id- Unique identifier for the matchtitle- Title of the matched contenturl- Source URL where the match was foundmatchedWords- Number of words that matchedmetadata- Additional information about the source (author, organization, publish date, etc.)
Example payload structure
Moderating Content for Safety
To ensure that your published content is safe and adheres to your community standards, you can use the Copyleaks Text Moderation API. This API allows you to scan text for harmful content across more than 10 categories, including hate speech, adult content, and other inappropriate material.Submitting Content for Moderation
To moderate a piece of content, send a POST request to the/v1/text-moderation/{scanId}/check endpoint. In the request body, you will provide the text to be analyzed and specify which content moderation labels you want to check for.
For example, a publisher might want to check for toxicity, profanity, and hate speech:
Example Moderation Request
Understanding the Results
The API will respond with a detailed analysis, pinpointing the exact segments of text that were flagged and for which categories. This allows you to build a workflow to automatically handle or review content that violates your policies. For a complete list of supported categories, see the Content Moderation Labels documentation. To get started with your integration, follow the Moderate Text Content guide.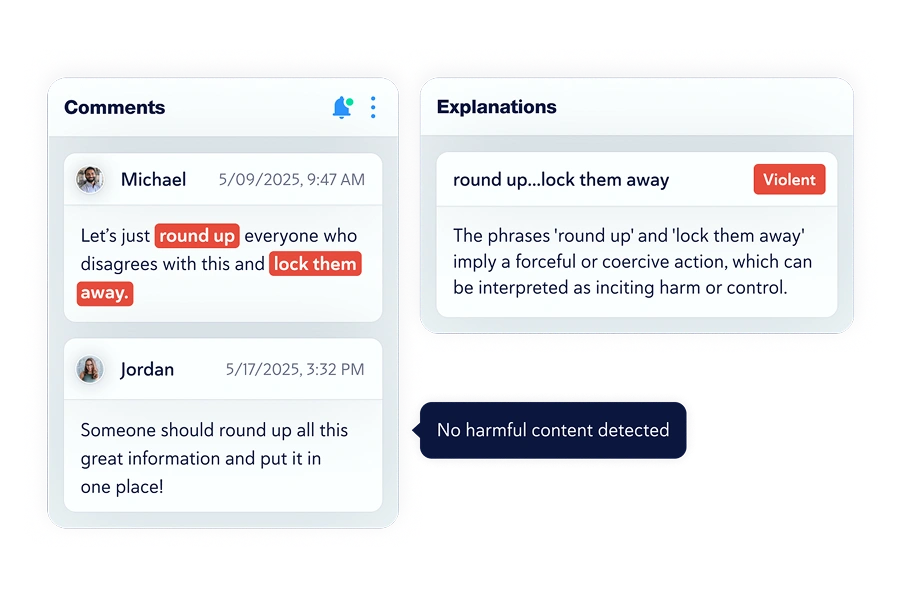
Detecting AI-Generated Content
You may also want to detect when content is generated by AI models. This can help you ensure that your published material meets your authenticity standards.- To check for AI-written text, set the
properties.aiGeneratedText.detectparameter totrue. - Your AI detection results are delivered to a dedicated export webhook. For an example of how the data will be structured, see the Export AI Detection Response documentation.

Verifying Image Authenticity
In an era of visual misinformation, verifying the authenticity of images is essential for maintaining reader trust and editorial integrity. AI-generated images can be used to create fake news, doctored evidence, or misleading content that can damage a publisher’s reputation. Our AI Image Detection API helps publishers identify synthetic images from all major AI generators, ensuring that all visual content meets your authenticity standards before publication. AI Image DetectionEnhancing Content Quality with Grammar Checker
Beyond detecting problematic content, publishers can also leverage Copyleaks to improve the quality and professionalism of their written material. By enabling Grammar Checker within your authenticity scan, you can ensure that your content meets the highest editorial standards before publication.Supporting Editorial Excellence
Grammar Checker is designed to help publishers maintain consistent, high-quality content across all publications:- Grammar and Mechanics: Catch spelling mistakes, comma errors, subject-verb disagreements, and comprehensive grammar issues
- Sentence Structure: Identify run-on sentences, fragments, and awkward phrasing to improve readability
- Word Choice: Suggest better vocabulary and catch misused words or homophones
- Multi-Language Support: Provide assistance in English, German, Spanish, French, Italian, and Portuguese
Grammar Score Assessment
The Grammar Checker provides a comprehensive Grammar Score that breaks down writing quality into two key areas:- Corrections: Detailed grammar, mechanics, and style suggestions
- Insights: Analysis of writing patterns, sentence length, and readability
Integration Options
You have two ways to integrate Grammar Checker capabilities:-
Integrated with Authenticity Scanning: Enable Grammar Checker alongside your plagiarism and AI detection scan by setting the
properties.writingFeedback.detectparameter totruein your authenticity scan request. The Grammar Checker results will be included in your scan completion webhook. - Dedicated Grammar Checker API: For standalone grammar and writing quality checks, use the dedicated Grammar Checker API endpoint. This is ideal when you only need writing feedback without plagiarism or AI detection.
Support
Should you require any assistance or have inquiries, please contact Copyleaks Support or ask a question on Stack Overflow with thecopyleaks-api tag.
Next Steps
Check for Plagiarism
Detect plagiarism in text documents using the Copyleaks API. Search billions of sources to find unoriginal content.
Moderate Text
Scan and moderate text content for unsafe or policy-relevant material across 10+ categories.
Schedule a Live Demo
Want to see how internet plagiarism detection works with your specific content? Our technical team can walk you through live examples of scanning against billions of online sources, including academic journals and websites.